
When trying to secure access to a specific sensitive Google Cloud resource, you’re likely familiar with going to the resource’s IAM permissions page in the Cloud Console. This view will show principals with direct permissions to access the resource, including permissions inherited from parent resources.
However, this excludes a common security vulnerability in many Google Cloud configurations: transitive access via service accounts.
What is transitive access?
Google Cloud Service Accounts can be principals in IAM policies in the same way that users and groups can be. This allows workloads authenticated as that service account to access those permissions. However, some human users may also have IAM permissions to authenticate as the service account, either directly on the service account or a parent resource (project, folders, or the organization). If a user can successfully authenticate as the service account, they gain access to all the IAM permissions associated with that account.
Permissions that allow transitive access
If a user or group has any of the following permissions on a service account, they are able to authenticate as the service account:
Detecting transitive access
Required Permissions
You will need the following IAM predefined roles:
roles/cloudasset.viewer
roles/iam.roleViewer
roles/iam.securityReviewer
Google Policy Analyzer
Google Policy Analyzer supports detecting transitive access.
You can use the analyzeIamPolicy API route in the Cloud Asset API.
You’ll need to call this route with scope set to organizations/{YOUR ORG ID} ,analysisQuery.resourceSelector.fullResourceName set to the full resource name of your desired resource (see documentation here for determining the full resource name), and analysisQuery.options.analyzeServiceAccountImpersonation set to true.
A sample query for access to Cloud Storage bucket test inside organization 123 would look like the following:
Unfortunately, Google does not include the iam.serviceAccounts.setIamPolicy permission in this analysis. However, it does not directly give the user access to authenticate as the service account, but a user could give themselves one of the other permissions and then be able to authenticate, so this still allows transitive access.
To additionally search for this permission, you’ll need to make a policy analyzer query for each of the service accounts returned in the results from the previous query. You’ll want the resource to be set to //iam.googleapis.com/projects/PROJECT_ID/serviceAccounts/SERVICE_ACCOUNT_EMAIL and to specify the permission to analyze you can set analysisQuery.resourceSelector.accessSelector.permissions to [iam.serviceAccounts.setIamPolicy]
Alternative Methods
Google recently announced their plans to restrict access to the Policy Analyzer API only to Security Command Center paying customers. If you are unable to use the Policy Analyzer API, it becomes more complicated to detect transitive access, but it’s still possible. We’ll walk through how to do so using other Google APIs.
You must first find the service accounts that have relevant permissions on your desired resource, and then find all principals who have access to authenticate as those service accounts.
Find risky service accounts
IAM Console
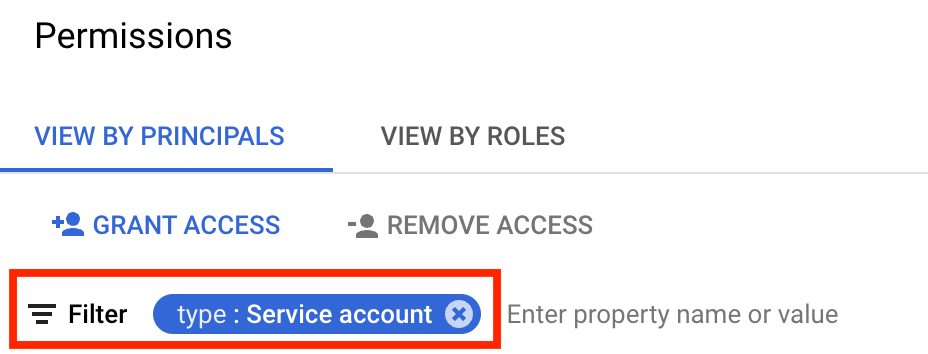
Navigate to the “IAM permissions” page for your desired resource. For example, to view access on a project, you would navigate here.
Type “Service account” in the filter bar in order to view only service accounts.
REST API
A principal may have access on a resource by directly having permissions on the resource, or they may have permissions on any parent of the resource in Google’s resource hierarchy. In order to query all IAM policies that apply to the resource, you’ll first need to find all the parents of the resource.
In order to do this, use the Cloud Asset Inventory searchAllResources endpoint. Search for your target name, which can be done via setting query to name:{RESOURCE_NAME} and scope to organizations/{YOUR_ORG_ID}
The response contains a parentFullResourceName field with the name of the parent resource. You’ll need to repeat this query with the parent name, until you receive a result with parentFullResourceName equal to the organization.
Now, query the Cloud Asset Inventory’s searchAllIamPolicies API route in order to find service accounts with permissions on your desired resource. To do so, set scope to organizations/{YOUR_ORG_ID} and include the following (space-separated) in query :
resource:(name1 OR name2 OR name3)and so on, for each of the resources in the hierarchy
memberTypes=serviceAccountto only show service account
policy.role.permissions:{SERVICE}*where{SERVICE}is replaced with the name of the Google service in which your target resource is located. For example, if it is a Cloud Storage bucket this would bepolicy.role.permissions:storage*or for a BigQuery table it would bepolicy.role.permissions:bigquery*
This will give you all the service accounts with access on your resource. Now, you will need to analyze the principals that have access to each service account.
Analyze service account access
Console
For each of the service accounts we discovered in the previous step, we can navigate to their IAM page in the Cloud Console either by going to the list of Service Accounts in the project and selecting the relevant ones, or by directly going to console.cloud.google.com/iam-admin/serviceaccounts/details/{SERVICE_ACCOUNT_ID}/ , replacing {SERVICE_ACCOUNT_ID} with the unique ID of each service account.
This page will show all the principals with roles on the service account. The following predefined roles contain permissions that allow service account authentication (and you will also want to check custom roles for the permissions listed above):
roles/editor
roles/owner
roles/backupdr.computeEngineOperator
roles/cloudmigration.inframanager
roles/dataproc.hubAgent
roles/earthengine.appsPublisher
roles/iam.securityAdmin
roles/iam.serviceAccountOpenIdTokenCreator
roles/iam.serviceAccountTokenCreator
roles/iam.serviceAccountUser
roles/iam.workloadIdentityUser
REST API
Use the Cloud Asset Inventory’s searchAllIamPolicies API route with scope to organizations/{YOUR_ORG_ID} .
For the query, include the following:
resource:(name1 OR name2 OR name3)and so on, for each of the service accounts identified in the previous step
policy.role.permissions:(iam.serviceAccounts.actAs OR iam.serviceAccounts.getAccessToken OR iam.serviceAccounts.getOpenIdToken OR iam.serviceAccounts.implicitDelegation OR iam.serviceAccounts.setIamPolicy OR iam.serviceAccounts.signBlob OR iam.serviceAccounts.signJwt)to include all permissions that allow transitive access
These results will show you all principals with transitive access to your desired resource. If there are any service accounts in the results, you should repeat the previous steps using those service accounts in order to detect access resulting from chaining service account impersonation. For example, a user may be able to impersonate service account B, which can then impersonate service account A, which has access on the resource. This chain can be arbitrarily long.
Best practices for service account keys
If a user has access to a service account key, it can be used to directly authenticate as the service account even if they do not have any IAM privileges on it. This is another, much harder to track, path for transitive access, and for this reason it is best practice to avoid creating service account keys unless absolutely necessary. To learn more about how you can secure service account keys, see our blog post Investigate Service Account Key Origins and Usage.
Secure Google Cloud resources for free with P0
To easily view all access on a resource classified by risk severity, sign up for P0 for free and conduct an IAM assessment in fifteen minutes. P0 will show you all your cloud principals (human and service accounts) along with all resources they have access to and information about their authentication history. If you want to lock down access to a sensitive resource, P0 makes it easy to find all the permissions you need to remove and will alert you if any changes to your IAM configuration cause the resource to be broadly accessible again.